|
by Howard Berkowitz
Another Kind of Policing: Connection Admission ControlConnection admission control operates on the theory that it is better to have a lesser number of sessions receive exactly the QoS they need than to have a greater number of sessions that do not receive the desired QoS. ATM has CAC.
The classic example of connection admission control is "all circuits busy" in the public switched telephone network (PSTN), accessed either by analog or ISDN interfaces.
RSVP, an IETF standard [RFC 2205] also refuses to allow a flow to start if there is insufficient network-wide reservable bandwidth to support the RSVP flow. RSVP is flow-oriented, as opposed to connection-based. It can be used to deliver IETF-standard Integrated Services Guaranteed Service.
It also depends on WFQ, so you must understand WFQ before delving deeply into RSVP. In Cisco's implementation, the relation between RSVP and WFQ is that RSVP allocates buffers and schedules packets using WFQ, and also uses specific WFQ queues for guaranteed bandwidth. Let's now consider the various ways that RSVP can reserve bandwidth for flows.
Distinct reservations support single information streams that cannot be shared, such as a VoIP call. Such flows are always unicast.
Shared reservations apply to applications where some oversubscription is perfectly acceptable, such as an audio conference where only a subset of the speakers will talk at any time. The reservation is made for the audio conference class, not the individual senders and receivers. Such reservations often involve multicasting.
Since multicasts inherently have shared resources, RSVP allows multicast merging.
While the original concept of RSVP allowed individual hosts to make reservations, it was clear from the beginning that this would not scale to extensive use. Indeed, the RSVP RFC states that RSVP was never intended for use beyond the scale of an enterprise.
RSVP, however, has evolved into a means of signaling for setting up MPLS tunnels. By assigning many like flows to a tunnel with common QoS, we come up with a much more scalable mechanism. Other RSVP techniques for scaling include flow merging.
RSVP is what is called a soft state protocol, which is intermediate between connection-oriented and connectionless. It has no explicit connection command, but the RSVP reservation process begins when an RSVP-capable interface receives a PATH protocol message.
Other soft state protocols include IGMP.
While soft state protocols do not have explicit establishment phases, they can have explicit or implicit phases or both as the means of teardown. RSVP does have an explicit teardown message to terminate the reservation before the expected timeout.
Before you can understand RSVP, you will need to understand Weighted Fair Queuing (WFQ). Even in Cisco, there are two basic kinds of WFQ: Flow-Oriented (WFQ) and Class-Based (CBWFQ). Low-Latency Queuing builds on CBWFQ. If you look into the computer science literature, you will find there are even more theoretical types of fair queuing.
Table 4. Overview of Queuing Mechanisms
| Discipline | Overview | Flow-Oriented? |
| PQ | Guarantees that high-priority traffic will get through | No |
| CQ | Guaranteed minimum bandwidth for traffic meeting rule | No |
| WFQ | Yes | |
| CBWFQ | Yes, with special cases | |
| LLC | WFQ with PQ for voice | Yes, with special case |
Basic or legacy WFQ, which has been present by default on interfaces slower than 2 Mbps since release 11.0, sorts flows into up to 256 queues. When I encountered the first description of the Weighted Fair Queuing (WFQ) feature, I wondered if it had been dreamed up by some sales droids over a long and liquid lunch. It seemed far too simple to work, although the original implementation had a very simple classification algorithm. As I investigated further, I found it really worked well for a wide range of applications, although it was extremely simple to implement.
In the simplest terms, WFQ gives the highest transmission priority to short packets with high precedence. It calls the transmission priority weight, and calculates weight by the rule of Equation 1. The actual criterion for the next packet to send is "Send the packet with lowest sequence number," with the sequence number determined by Equation 2.
Flow weights are determined as:
Equation 5. Flow Weight in WFQ
weight = 4096/(IP Precedence + 1)
Assume that we queue simply on IP precedence and length. As packets arrive, they are assigned sequence numbers according to:
Equation 6. WFQ Sequence Number
sequenceNumber = currentSequenceNumber + (weight * length)
where currentSequenceNumber is:
if the queue is empty, the currentSequenceNumber is equal to
the sequence number of the last packet queued for transmission in the subqueue.
The first packet queued in the subqueue will have a currentSequenceNumber of zero.
if the subqueue is nonempty, the currentSequenceNumber will become
the sequence number of the last packet on the subqueue.
As with all things, the initial implementation did not cover all future requirements. The first implementation drew a very useful distinction between the characteristics of text-interactive and bulk data transfer applications. It assumed that interactive applications have low volumes and that non-interactive, bulk transfer applications have high volumes.
Once packets were assigned to a flow, the flow monitor kept track of the volume associated with individual flows. Based on their volume, the flows are assigned to high- or low-volume queues. Low-volume flows are prioritized over high-volume flows, on the assumption that low-volume flows are interactive and high-volume flows are bulk transfers that attempt to maximize their window size.
WFQ did not, however, consider the special needs of delay-sensitive traffic such as VoIP. Improvements to the implementation dealt with the needs of those services, first allowing precedence to be considered.
As opposed to Custom Queuing (CQ), WFQ does not guarantee minimum bandwidth. It does attempt to give all queues access, depending on the packet length and precedence in all queues.
Assume that there are four queues, each with 100-byte packets, in precedences 0 through 3. First, you must sum the bytes in queue for all flows:
Equation 7. WFQ Total Bytes
TotalBytes = 0 For Q1 to Qn TotalBytes = TotalBytes + Bytes (Q) For Q1 to Qn BytesForQueue(Q) = TotalBandwidth / (Precedence + 1)
At this point, each queue will get 25% of the bandwidth (Equation 7). Figure 8 reveals another interesting truth about RSVP and its interaction with non-RSVP traffic.
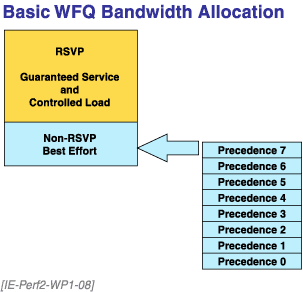
Figure 8. Basic WFQ Bandwidth Allocation
You can only allocate 75% of the bandwidth of an interface to RSVP. That means there will always be 25% available for "best effort" traffic.
Having a given part of the bandwidth, however, does not ensure the transmission order. After a packet is sent, WFQ re-sorts the queues and looks at the sequence number (Equation 6) of packets in each queue. It will then send the packet with the smallest sequence number.
Table 5. WFQ Statistics from show queuing
| Parameter | Minor parameter | Meaning |
| Output queue | drops | Number of packets dropped because they exceeded threshold or max total |
| max total | Maximum number of interface buffers that can be used by WFQ | |
| size | Total number of packets in the queuing system | |
| threshold | Maximum number of packets normally allowed in a subqueue | |
| Conversations | active | Number of active flows |
| max active | Number of active flows | |
| threshold | Number of active flows | |
| Per-queue statistics | depth | Number of packets in this queue |
| weight | Weight of each packet in queue | |
| discards | Packets dropped because they exceeded congestive discard | |
| tail drops | Packets dropped when max total was exceeded | |
| interleaves | Count of fragments allowed by link fragmentation |
WFQ is the default for links that have bandwidth not greater than 2.048 Mbps and that do not use data link protocols that do link-level retransmission, compression, or encryption. Nevertheless, you may need to code WFQ explicitly, if for no other reason than to change default options. Under interface configuration mode, the command is:
fair-queue [congestive-discard-threshold [dynamic queues] [reservable queues]]]
The congestive discard threshold is the maximum number of packets that can be in a queue, and defaults to 64. Dynamic queues specify the number of subqueues, with a default of 256. Reservable queues can handle RSVP flows.
In practice, Frame Relay congestion notification mechanisms are rarely of much use to routers. Routers running WFQ, however, are an exception. When the FR interface detects BECN, DE, or DECN flags, it adjusts the weights used for the associated flows.
Since reservations are end-to-end, they logically are initiated by hosts to other hosts. In RSVP for VoIP, however, the VoIP router initiates the reservation. For example, when configuring VoIP dial peers, you use the req-qos command to initiate a reservation for the call.
Consider the requirement in Figure 9. There are six branch offices, each with two routers. One of the routers is reserved for VoIP and the other is reserved for non-voice traffic. Only the VoIP router needs reserved bandwidth.
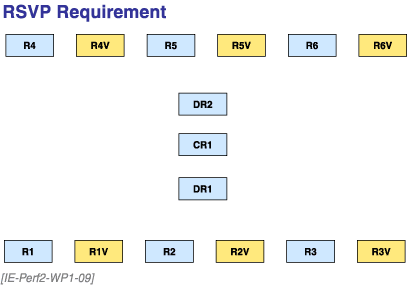
Figure 9. RSVP Requirement
Branch office routers connect to one of two distribution routers, which, in turn, connect to a core router (Figure 10). You must be able to reserve bandwidth end-to-end among the branch VoIP routers.
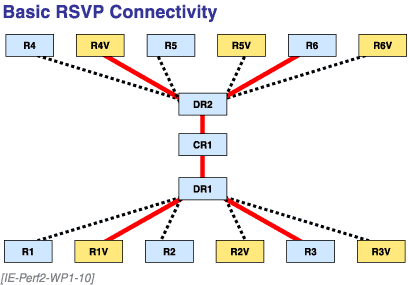
Figure 10. Basic RSVP Connectivity
This creates the first connectivity requirement. Obviously, you have to configure RSVP on the relevant routers.
Things become more complex when we introduce fault tolerance (Figure 11). All the interfaces in possible paths have to have RSVP enabled, or the path, while pingable for normal IP, can't be used for RSVP.
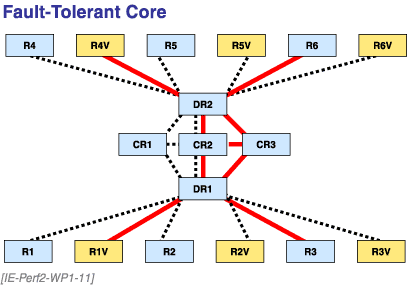
Figure 11. RSVP with Fault-Tolerant Core
So far, we've assumed an interface is either RSVP or not RSVP. In fact, an RSVP-enabled interface can also carry non-RSVP traffic. If the RSVP traffic is unicast, each flow will be separate and will consume separate resources in a shared medium.
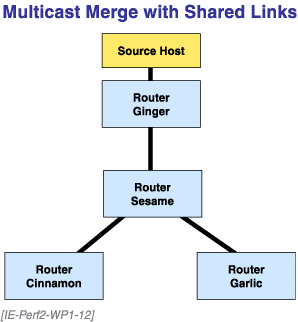
Figure 12. Multicast Merge with Shared Links
When the RSVP traffic is multicast, the flows can merge in a common medium, saving bandwidth.
RSVP has to be enabled on a per-interface basis and given a total reservable bandwidth. In principle, it can be enabled on all types of interfaces, but in practice, it is used on point-to-point and NBMA interfaces. You will want to be sure to set the interface bandwidth command, as it would not be terribly useful to take the default T1 bandwidth on a fractional T1 interface that has a maximum of 256 Kbps.
When you configure RSVP on a subinterface, it will allow you to reserve only the lesser of the subinterface bandwidth and the physical interface bandwidth (i.e., the default or explicit bandwidth on the physical interface).
The default reservation is 75% of the total, but you can set other values. You can also set the maximum bandwidth allowable for a single flow.
ip rsvp bandwidth [interface-kbps] [single-flow-kbps]
It's good practice to restrict which neighbors can request reservations to a router. Otherwise, you are in danger of losing control of the bandwidth requirements in your network.
You do this in interface configuration mode with the ip rsvp neighbor access-list-number command. Note that you can set different neighbors for each RSVP-enabled interface.
RSVP setup proceeds in a direction opposite to the direction in which bandwidth is being reserved. See Figure 13.
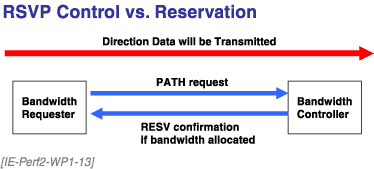
Figure 13. RSVP Control versus Reservation
The originator of the reservation request sends an RSVP PATH message in the direction of the far-end router.
There are three ways to make this reservation. (See Table 6.)
Table 6. RSVP Reservation Types
| Reservation Style | Scoping |
| Fixed Filter (FF) | Single address |
| Wild Card Filter | Explicit list of source addresses ("demand side") |
| Shared Explicit | Identifies flows that can use certain resources ("supply side") |
If routers along the path can allocate bandwidth on their outgoing interface, they forward the PATH message to the next hop. When the PATH message reaches the last hop, that router sends a RESV message onto the route on which the PATH messages arrived, routing them in reverse order of hops back to the sender and confirming the reservation. It should be obvious that if the end-to-end path changes, the bandwidth has to be reserved again.
An RSVP-enabled interface releases a reservation if it does not receive a PATH message. Lying to protocols can be a very useful thing. For example, if you only used RSVP to request voice bandwidth when you were actually making a call, the bandwidth might not be there when you are about to receive a call. IOS has commands that allow you either to force a router to believe it is continually sending a PATH message (ip rsvp sender) or to force a router to actually send continuous PATH even when there is no RSVP request to do so. The latter is intended primarily for debugging.
Remember that RSVP is a soft state protocol. Continuing PATH messages keep the reservation alive.
Table 7. RSVP Functions and Associated Commands
| Desired Function | Command/Environment |
| Accept PATH or RESV from real host | Host on subnet with interface that has RSVP enabled with ip rsvp bandwidth |
| Generate PATH as if it were a host | ip rsvp sender-host |
| Generate RESV as if it were a host | ip rsvp reservation-host |
| Act as if it were an intermediate router sending and receiving PATH | ip rsvp sender |
| Act as if it were an intermediate router sending and receiving RESV | ip rsvp reservation |
And now, the commands themselves. The parameters for all are defined in Table 8.
Table 8. RSVP Command Parameters
| Parameter | Meaning |
| session-ip-address | IP address of the sending host for unicast, multicast IP address |
| sender-ip-address {tcp | udp | ip protocol} | TCP, UDP, or IP protocol number |
| previous-hop-ip-address | Address or name of receiver or the router closest to the receiver |
| previous-hop-interface | Ethernet, loopback, serial, or null |
| next-hop-ip-address | Address or name of receiver or the router closest to the receiver |
| next-hop-interface | Ethernet, loopback, serial, or null |
| session-dport session-sport {ff | se | wf} | Source and destination port numbers (as numbers, not keywords) |
| {ff | se | wf} | Reservation type
|
| {rate | load} | Guaranteed service | controlled rate |
| bandwidth | Kbps to be reserved, up to 75% of interface |
| burst-size | Kilobytes |
We have already discussed one proactive way to avoid congestion: connection admission control. Random Early Detect is another way to avoid congestion, if the Transport- and higher-layer protocols in the flows respond intelligently to packet loss that can be attributed to congestion [RFC 2309].
I like to visualize RED as a scene from one of the many "lifeboat" movies, where the boat has too many passengers for all to survive. Depending on the script, some passengers sacrifice themselves or are otherwise disposed of by the boat captain. The RED queuing disciplines are somewhat like that, but with happy endings.
Basic, as opposed to Weighted, RED has a single queue. The RED code monitors the length of this queue to see the trend of queue growth. In other words, it keeps track not just of the number of packets in queue but also of the rates at which they enter and leave. This predictive approach is quite different from those of other queuing mechanisms that use binary rules (e.g., PQ) or fixed allocations (e.g., CQ).
When RED decides there is plenty of capacity, it does nothing. If it sees that the queue occupancy has reached a critical limit, it refuses to accept any new packets until occupancy has dropped to an acceptable level. Between these two limits, the unique aspects of RED come into play.
Going back to our lifeboat analogy, the boat captain decides that the good of the many is more important than the good of the one or of the few. To try to make fair the sacrifice of a few, he plays Russian roulette. He loads a revolver with a single bullet, spins the cylinder, points it at the first passenger in line, and pulls the trigger. If the passenger is lucky, there is only a click as the hammer falls on an empty slot. The boat officer goes sequentially through the passengers, eventually getting a BANG. The victim is tossed overboard, and the officer again evaluates the number of passengers in the boat queue. He repeats the process until the queue is of acceptable size.
A tragic scene, of course, with real people in a boat. However, in this case, we are dealing with packets, many of which are under TCP control and can be retransmitted, and others of which are under UDP control with applications that can accept some packet loss. I have long commented that with TCP, death is nature's way of telling you to slow down.
The benefit of RED is most obvious with properly implemented TCP, or when UDP is used with higher-level protocols that reduce transmission rates if they sense congestion. If a packet is discarded, eventually the sender's acknowledgement timer will expire because the packet never reached its destination, where the acknowledgement would be generated.
TCP operates on the assumption that packet loss is due to congestion, so it will slow the rate at which it transmits. Eventually, if enough different TCP packets are discarded to cause many TCP connections to slow down, packets will be generated at a rate the queues can successfully handle. The happy ending comes because TCP packet death is only a temporary thing: the unfortunate packets will be retransmitted and eventually get through.
Weighted RED (WRED) considers IP precedence and creates multiple queues. Again, if this were a lifeboat, the boat captain would begin by shooting the third-class passengers. If there were still a problem after third class was empty, only then would the captain move to second class. The premium passengers would get the best chance of survival.
So, WRED begins with packet classification, which is based on IP precedence and RSVP status. Using the classification rules, it assigns packets to queues. Traffic can be identified as destined for a certain queue either with RSVP or by settings of the TOS bits in the IP header. RSVP flows generally are exempt from RED.
WRED then monitors the queues to track their average size, and predicts the rate at which the queue is growing (or not). Queue length estimation involves tracking the average queue length over time as an exponentially weighted moving average, avgk (Equation 8). In basic, nonweighted RED, this time-averaged queue length is used to select the queue from which traffic is dropped when the congestion threshold is approached.
Equation 8. Exponentially Weighted Moving Average for WRED
avgk = (1 - wq) avgk-1 + (wk*qk) where w is a weight for queue q k is a time
When this threshold is reached, (W)RED drops packets, but random packets in the queue rather than tail drop. This random process operates within two limits: the min threshold (also called trigger) and max threshold. The drop rules are as follows:
Queues whose average length is less than or equal to min threshold will never have packets dropped.
In a queue for which the average queue length is greater than max threshold, all packets will be dropped.
In the event of congestion, packets in a queue whose length is between min threshold and max threshold will be dropped with a probability proportional to the queue length.
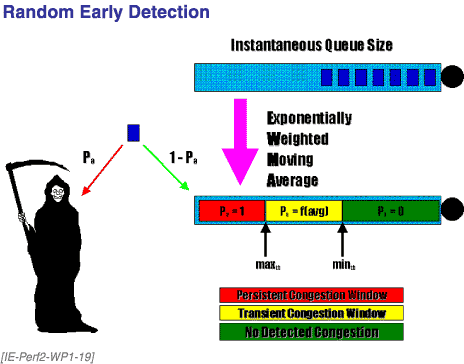
Figure 19. Random Early Detection
You enable RED with a single interface subcommand, random-detect. Use show interface random to see the thresholds, traffic volumes, and drops.
Reactive congestion management is intended to operate when the outbound bandwidth is congested, as opposed to trying to prevent congestion. The earliest Cisco implementations, when queuing was enabled, always queued traffic to an outbound interface whether or not the output link was congested. Performance improved when developers realized it seemed silly to delay traffic in queues if the output interface was available. Implementations then began putting traffic on a direct, not a queued, path when no congestion was present.
Cisco's reactive congestion management functions were restricted to output interfaces in early IOS releases . In somewhat later IOS versions, input queue management was supported, but had a significant performance impact on the entire router. Current implementations, however, are generally performance-indifferent as to whether certain queuing is done on input or output. Classification and marking, of course, have to take place on input.
Finding the Queuing MechanismIn recent releases, do a show interface command. The resulting display will show the queuing or other discipline and the important statistics for it. |
Assuming that R3 has an infinite supply of buffers, R1 and R2 will share the line. The line can be considered congested. Congestion occurs whenever the offered load is greater than the capacity of the resource that services the load.
In a pure world, there are only three ways to deal with congestion:
Reduce the offered load
Increase the bandwidth
Pray to St. Jude, the patron saint of lost and hopeless causes
In the real world, a certain amount of congestion may be perfectly acceptable. Alternatively, much as airlines offer first class and coach, some traffic may receive different treatment when congestion exists. If R1 is considered first class while R2 is coach, the router might follow a strategy of always preferring R1's traffic. With such a strategy, R1 would be delayed at most by one of R2's frames.
Is this a realistic model? Refer to the general rule of networking design: it depends. If both source hosts send constantly, the approximation of 32 Kbps is reasonable. Interactive applications, however, rarely send constantly. They are bursty. There is human "think time" between queries and responses. As the pauses between the transmissions of R2 and R1 grow longer, the probability increases that any given transmission will not have to wait for another transmission ahead of it. See Table 22 for a range of strategies, remembering that CAC and policy routing, as well as input policing and shaping, are other tools in the QoS toolbox.
Table 22. Output Prioritization Strategies
| Discipline | Number of Queues | Queuing and Drop without Queuing Rules | Rules for Deletion from Queues | Queue Scheduling Rules |
| First-in-first-out (FIFO) | 1 | First in. | Buffer exhaustion (appears as output drop in show interface) | First out |
| Preemptive for high priority (Priority Queuing) | Fixed, usually 3 - 4 | Programmed. Dropped if queue full. | If number of packets exceeds limit for priority class | High to low, servicing highest as long as traffic in queue |
| Guaranteed minimum bandwidth (CQ/CBQ) [1] | Programmable | Programmed. Dropped if queue full. | If number of packets exceeds queue limit (default 20) | High to low, servicing each queue up to programmed number of bytes and/or packets |
| Preference for high priority and short packet length; self-adjusting (WFQ) | Up to 256 | IP precedence (diffserv) if implemented. Lower-volume flows to higher-priority queue. | High priority as long as there is traffic, low priority for 1 packet before high is checked | |
| Proactive congestion avoidance (RED) | Usually 8 or more (diffserv plus RSVP flows plus UDP) | Drop packets in drop-eligible queues trending toward congestion. | Random packets in congested queues | Complex algorithm |
| Guaranteed minimum bandwidth with less configuration and finer granularity (CBWFQ) | Guaranteed minimum bandwidth at a flow granularity | Exceeds congestive-discard-threshold | ||
| Guaranteed minimum bandwidth, except it can be preempted for one type of traffic | Priority Queuing for critical traffic class plus CBWFQ for rest | PQ for the special queue, CBWFQ for the others. | Exceeds priority queue or CBQ queue-limit | High priority as long as there is traffic, then proportional shares of available bandwidth |
[1] Class-based queuing is the more general network engineering term for what Cisco has called Custom Queuing, and indeed is the term Cisco is using in new modes such as CBWFQ.
Priority Queuing was the first method introduced by Cisco, and remains quite simple to configure. It is still quite relevant to situations where certain traffic MUST be sent, even if other traffic is completely starved of bandwidth.
Network management traffic such as routing updates and keepalives must be sent. A typical early application for Priority Queuing was sending IBM traffic over a merged enterprise network. TCP/IP is much more tolerant of drops and delays than many early IBM protocols.
To use Priority Queuing, you code priority list statements to specify both classification and action, with the action being assignment to queues. These are much like access list statements, except the action on matching is assigning traffic to a queue.
if HIGH is not empty
then send next HIGH packet
else if MEDIUM is not empty
then send next MEDIUM packet
else if NORMAL is not empty
then send next NORMAL packet
else send next LOW packet
|
Figure 20. Priority Queuing Logic
As the algorithm in shows, if there is enough HIGH priority traffic to keep the HIGH queue full, no other queue will ever be serviced.
You configure PQ both globally, with priority list commands, and on interfaces, with priority group commands, much as you code access lists and access groups.
While it is possible to change the default queue lengths (), it is unwise to do so unless you have a thorough understanding of both your traffic patterns and of queuing theory. You use the priority-list list-number queue-limit command.
Table 23. Default PQ Queue Length
| Queue | Default slots |
| HIGH | 20 |
| MEDIUM | 40 |
| NORMAL | 60 |
| LOW | 80 |
In contrast to Priority Queuing , Custom Queuing does make sure that each class gets some bandwidth. You can think of it as a method for providing guaranteed minimum bandwidth. Use CBWFQ in preference to CQ when CBWFQ is available on the platform. CBWFQ is more powerful and easier to configure.
Figure 21 shows, in pseudocode, the logic of basic CQ. You configure n queues, along with a system priority queue, in a given allocation cycle. Each queue is given a byte count allocation, and, in principle, sends up to that number of bytes in each cycle (see "Basic CQ Configuration").
For i = 1 to n
if Q[i] is not empty
then send up to allocation[i] bytes
Next i
|
Figure 21. Custom Queuing Logic
You configure CQ both globally, with queue list commands, and on interfaces, with queue group commands, much as you code access lists and access groups. There are actually two types of queue-list commands, much as you may have multiple types of neighbor statements in routing protocol configuration.
The first is very much like PQ in that it assigns traffic to queues. There are a maximum of 16 user-configurable queues, plus a queue 0 used for routing updates and similar system traffic.
queue-list number protocol protocol-name queue-number queue-keyword keyword-value
The second type of queue-list command sets the bandwidth allocation per queue, as well as other queuing limits. The bandwidth allocation is indirect and is best seen in an example.
queue-list list-number queue queue-number
byte-count queue-size
If there is no traffic for a given queue, its bandwidth is distributed equally to the other queues.
Let's try an example.
Table 24. Custom Queuing Goals
| Traffic Type | Packet Size | Percent Bandwidth |
| SMTP | 4000 | 25% |
| HTTP | 1500 | 50% |
| Telnet | 100 | 25% |
First, do the classification configuration:
queue-list 1 protocol ip 1 tcp 25 queue-list 1 protocol ip 2 tcp 80 queue-list 1 protocol ip 3 tcp 23
Now, let's see how you might allocate by byte count. If you use one packet of each traffic type, the sum of bytes in all queues is 5600.
Table 25. First Attempt at Byte Counts
| Traffic Type | Packet Size | Fraction | Percent Bandwidth |
| SMTP | 4000 | 4000/5600 | 71% |
| HTTP | 1500 | 1500/5600 | 28% |
| Telnet | 100 | 100/5600 | 2% |
Clearly, this doesn't give the appropriate minimum bandwidths. The HTTP is about half the bandwidth desired, so try doubling the allocation, with a new sum of 8100:
Table 26. Second Attempt at Byte Counts
| Traffic Type | Packet Size | Byte Count | Fraction | Percent Bandwidth |
| SMTP | 4000 | 4000 | 4000/8100 | 49% |
| HTTP | 1500 | 3000 | 3000/8100 | 37% |
| Telnet | 100 | 100 | 100/8100 | 1% |
Time to try again.
Table 27: Third Attempt at Byte Counts
| Traffic Type | Packet Size | Byte Count | Fraction | Percent Bandwidth |
| SMTP | 4,000 | 4,000 | 4,000/13,500 | 30% |
| HTTP | 1,500 | 4,500 | 3,000/13,500 | 22% |
| Telnet | 100 | 5,000 | 5,000/13,500 | 37% |
Refining again,
Table 28. Adequate Approximation of Byte Counts
| Traffic Type | Packet Size | Byte Count | Fraction | Percent Bandwidth |
| SMTP | 4,000 | 4,000 | 4,000/18,500 | 21% |
| HTTP | 1,500 | 4,500 | 8,000/18,500 | 43% |
| Telnet | 100 | 5,000 | 5,000/18,500 | 27% |
You are now fairly close, and this may be adequate. In most cases, the packet lengths will not be constant in each queue, so more refinement may be lost in the noise.
Now assign the byte counts:
queue-list 1 queue 1 byte-count 4000 queue-list 1 queue 2 byte-count 8000 queue-list 1 queue 3 byte-count 5000
Prior to IOS 12.1, a condition existed where a given queue could get more than its fair share of CQ bandwidth if the packet lengths for that queue were not well understood. When a queue is being serviced, a packet will be sent even if the total bytes in the current packet plus the bytes already sent in the cycle exceeds the byte allocation. If, for example, you set the byte allocation to 1000 but you had 750 byte packets, 1500 bytes would be sent in every cycle.
In 12.1, the IOS remembers the "deficit" of the last cycle (500 bytes in the previous example) and subtracts that deficit from the byte count available in the next cycle. This improves the equality of bandwidth allocation, but may cause oscillations in bandwidth as the queue goes between short and long byte counts.
To avoid oscillation, it might seem reasonable to assign large byte counts to each queue. The problem with doing so is that it takes a long time to service a queue that has both a large allocation and significant enqueued traffic. By the time the next queue can be serviced, a substantial delay can take place.
CBWFQ combines the guaranteed minimum bandwidth of CQ with the flow-level granularity and self-adjusting properties of WFQ. You configure it with the new modular CLI, rather than primarily with interface commands.
Table 29. Modular CLI Commands
| Map Type | Function |
| class-map | Defines classes for packets meeting class criteria |
| policy-map | Defines policy for classes |
| service-policy | Applies policies to interfaces |
Class-maps are somewhat like queue-list statements for CQ. The bandwidth allocation, however, takes place in the policy map.
The policy-map defines the amount of bandwidth assigned to a queue. However, you have more bandwidth control than in standard WFQ. You use the policy-map bandwidth clause directly as a percentage, rather than by the indirect ratios of CQ.
You also have control of the weight (i.e., the preference given to the class). As in WFQ, you can define a queue limit for the class (i.e., maximum packets that can be sent in any one cycle) and a maximum number of packets that can be queued for a class. Using the class-default clause of a class-map, you define a default class for all traffic that does not meet a class-map criterion.
When the default (and maximum) queue limit of 64 packets, or a smaller limit set with the policy-map queue-limit clause, is reached, the default action is to drop tail packets. Alternatively, you can specify WRED as the drop mechanism for CBWFQ using the policy-map random-detect clause. If you do this, you must not configure WRED for an interface where you configure CBWFQ with the WRED discard option.
You may specify a default class that will receive all traffic that does not pass an explicit classification rule. If you configure this class with WFQ, the traffic in it will be classified as best effort traffic.
Enable CBWFQ on interfaces with the service-policy output policy-map command. While the service-policy command of the modular CLI requires an input or output keyword, CBWFQ is applicable only to outgoing traffic.
LLC is an extension of CBWFQ with a special queue under PQ rules. In other words, the special queue is guaranteed service with no more than one packet delay, and can starve all other queues. If there is no traffic in the special queue, which is intended for voice, the LLQ interface follows CBWFQ rules.
LLQ is another queuing discipline primarily intended for VoIP over Frame Relay applications. While it could be used for other delay-sensitive applications, Cisco recommends you use it only for voice. LLQ is yet another of those QoS mechanisms that combine several existing methods. LLQ's specific combination is adding PQ to CBWFQ. With PQ, low-latency-dependent traffic such as voice will always be serviced first, before the next class or flow that would otherwise be serviced.
There actually are two ways to configure LLQ, one of which is outside the set of QoS commands. If you configure the IP Real Time Protocol (RTP), you can use the ip rtp priority commands to identify a range of UDP ports that will carry high-priority voice. If, however, you use a policy-map with the command, you get more flexibility. No longer are you limited to port numbers, but you can use all the match criteria that access lists provide. The policy-map subcommand is:
priority bandwidth
bandwidth is the minimum amount of bandwidth to be applied to this traffic type.
[IE-Perf2-WP1-F05]
[2005-08-01-00]
|